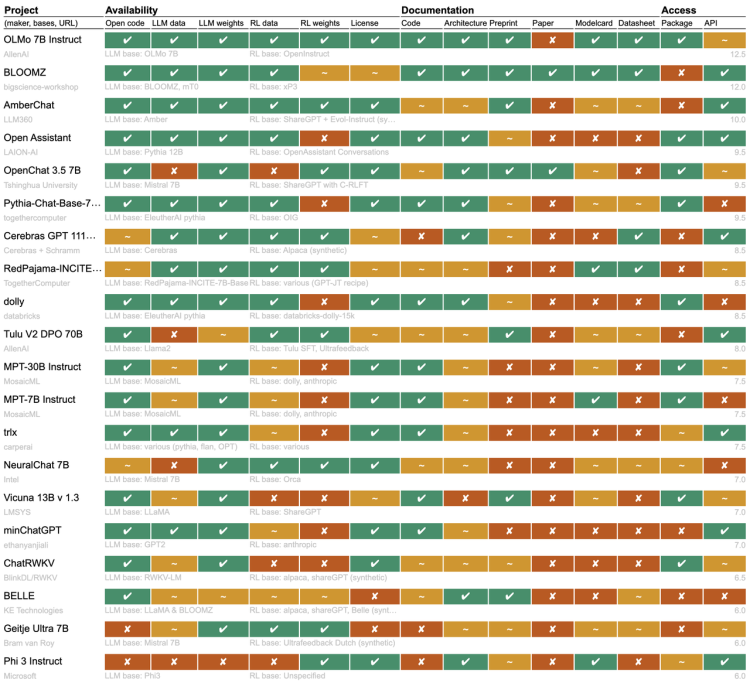
大模型行业,根本没有什么“真”开源?
大模型行业,根本没有什么“真”开源?最近一段时间开源大模型市场非常热闹,先是苹果开源了70亿参数小模型DCLM,然后是重量级的Meta的Llama 3.1 和Mistral Large 2相继开源,在多项基准测试中Llama 3.1超过了闭源SOTA模型。 不过开源派和闭源派之间的争论并没有停下来的迹象。
来自主题: AI资讯
8730 点击 2024-08-01 11:26
 搜索
搜索
最近一段时间开源大模型市场非常热闹,先是苹果开源了70亿参数小模型DCLM,然后是重量级的Meta的Llama 3.1 和Mistral Large 2相继开源,在多项基准测试中Llama 3.1超过了闭源SOTA模型。 不过开源派和闭源派之间的争论并没有停下来的迹象。
AI大神李沐老师时隔1年多,终于回归B站“填坑”经典论文精读系列了!

Meta、UC伯克利、NYU共同提出元奖励语言模型,给「超级对齐」指条明路:让AI自己当裁判,自我改进对齐,效果秒杀自我奖励模型。
今年的图形学顶级会议 SIGGRAPH 2024 上,老黄把扎克伯格请来了。

适逢Llama 3.1模型刚刚发布,英伟达就发表了一篇技术博客,手把手教你如何好好利用这个强大的开源模型,为领域模型或RAG系统的微调生成合成数据。
在Meta的Llama 3.1训练过程中,其运行的1.6万个GPU训练集群每3小时就会出现一次故障,意外故障中的半数都是由英伟达H100 GPU和HBM3内存故障造成的。

每3个小时1次、平均1天8次,Llama 3.1 405B预训练老出故障,H100是罪魁祸首?

不是大模型用不起,而是小模型更有性价比。
Meta 发布 Llama 3.1 405B,开放权重大模型的性能表现首次与业内顶级封闭大模型比肩,AI 行业似乎正走向一个关键的分叉点。扎克伯格亲自撰文,坚定表明「开源 AI 即未来」,再次将开源与封闭的争论推向舞台中央。

最近,Latent Space发布的播客节目中请来了Meta的AI科学家Thomas Scialom。他在节目中揭秘了Llama 3.1的一些研发思路,并透露了后续Llama 4的更新方向。